Springboot+ajax+mybatis实现简易网页
Springboot+ajax+mybatis实现简易网页
趁着周末又浅浅复习了一下结对编程用到的技术,重新制作了一个简单的demo练手,分享一下自己的理解~
Springboot框架
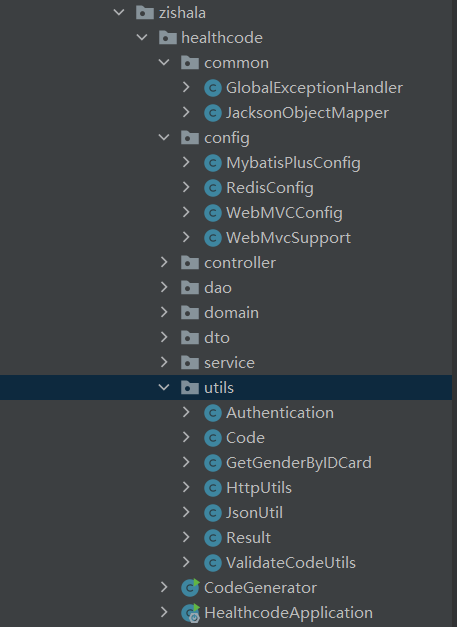
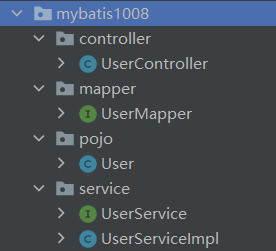
上学期,我在接触springboot框架之前没有接触过spring框架和Javaweb等知识,所以刚刚上手的时候还是非常的困惑不理解的。经过了一个学期断断续续的学习,加上假期(四舍五入也算)自己完成的博客,对springboot的结构和编写时的流程有了一些自己的理解:


- pojo层(entity层):用于定义数据库对象对应的属性,是存放实体类的文件夹,例如:user类等。可以使用lombok来自动生成构造方法和getter setter
1 | import lombok.AllArgsConstructor; |
- mapper层(dao层):是持久层,用于与数据库进行数据交互,mybatis就是一种应用广泛的持久层框架。在mapper层中,先设计接口,然后通过配置文件或者注解来实现crud操作。由于玩不明白配置文件,所以俺就选择了使用@Select注解(菜)
1 | import com.example.mybatis1008.pojo.User; |
- service层:是业务逻辑层,完成功能的设计。也是先设计接口,再创建要实现的类。在service层中,我们可以调用mapper层中的接口来进行业务逻辑应用的处理。service的impl是对service接口进行实现,把mapper和service进行整合的文件。封装Service层的业务逻辑有利于业务逻辑的独立性和重复利用性。

1 | //UserService |
- controller层:是控制层,调用service层中实现的功能来实现业务,控制请求和响应,进行前后端交互
1 | import com.example.mybatis1008.service.UserServiceImpl; |
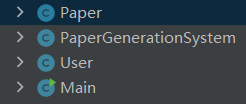
借用一张网图来清晰明了的总结一下结构~

mybatis
mybatis使用之前需要对项目进行一些配置,首先就是在maven中引入mybatis(具体maven文件在最后给出~),然后还需要在resources文件夹下新建一个mybatis-config.xml文件,其中的具体内容在mybatis的官网上可以找到,这里也给大家列出
1 |
|
这样我的mybatis就可以使用了(希望你滴也可以,这东西挺玄学的,第一次配的时候搞了半天),我采用的是直接在持久层使用@Select注解来写sql语句(见mapper层),自我感觉也挺方便清晰的,不过主流方案好像是在对应的配置文件中写,可能维护的时候更方便吧。
在使用时,直接创建mapper对象进行方法调用,即可实现其所对应的sql语句。
ajax
我更习惯用jQuery封装好的ajax,写法更简洁一点,原生的ajax区别也不算大。详见jQuery的ajax的简单应用
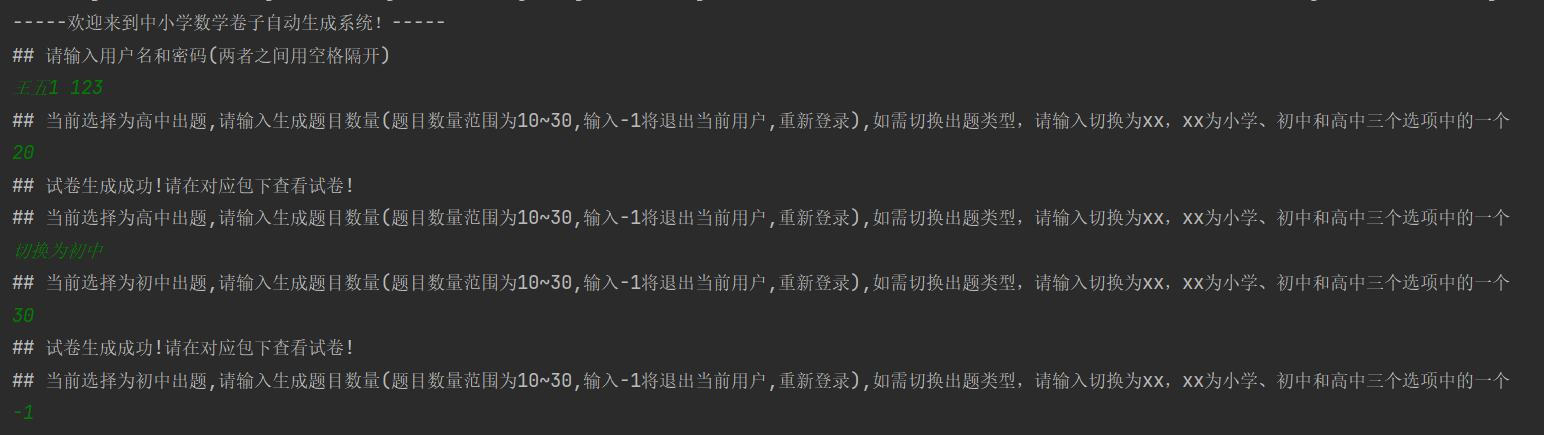
简单展示
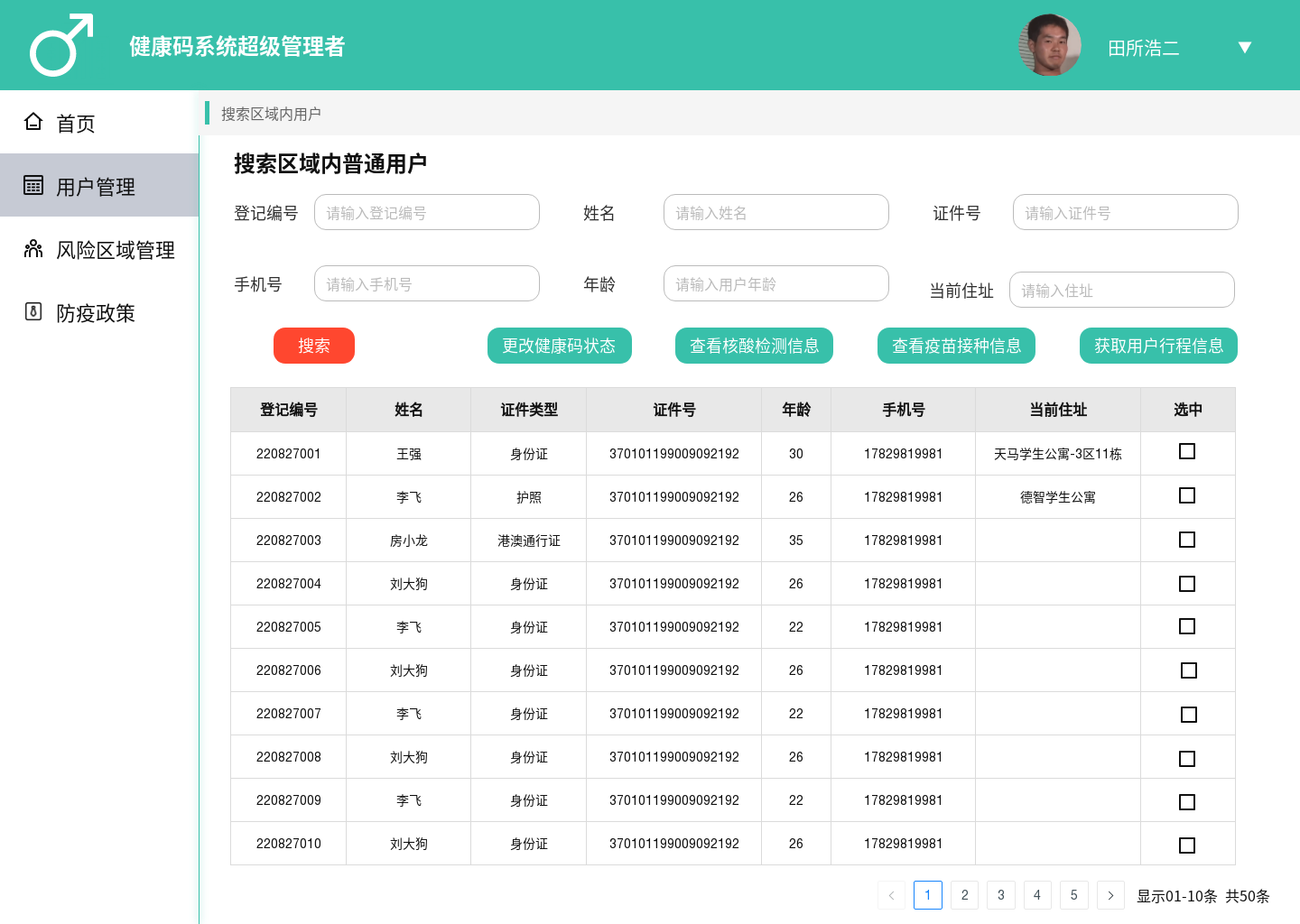
- 初始状态

- 点击获取,获取现有的用户信息

- 填写用户名和密码,点击修改,修改信息

界面没有做什么美化,项目结构也很简单,但麻雀虽小五脏俱全,使用这些技术就可以实现一个小小的web项目了。(本文源码下载)
由于缺少研究,作者目前只是简单知道一些注解的作用,对于xml文件的编写并不是很熟悉,很多地方暂时也不是很清楚。但是作者认为,不理解的时候也不需深究,熟练的使用对理解原理有着重要作用。当能做到熟练使用时,也许我们对自己未知的知识会产生一些新的理解。
希望本文能帮助大家对web项目的开发有一些新的认识!
最后附上maven配置
1 |
|
Springboot+ajax+mybatis实现简易网页
趁着周末又浅浅复习了一下结对编程用到的技术,重新制作了一个简单的demo练手,分享一下自己的理解~
Springboot框架
上学期,我在接触springboot框架之前没有接触过spring框架和Javaweb等知识,所以刚刚上手的时候还是非常的困惑不理解的。经过了一个学期断断续续的学习,加上假期(四舍五入也算)自己完成的博客,对springboot的结构和编写时的流程有了一些自己的理解:

- pojo层(entity层):用于定义数据库对象对应的属性,是存放实体类的文件夹,例如:user类等。可以使用lombok来自动生成构造方法和getter setter
1 | import lombok.AllArgsConstructor; |
- mapper层(dao层):是持久层,用于与数据库进行数据交互,mybatis就是一种应用广泛的持久层框架。在mapper层中,先设计接口,然后通过配置文件或者注解来实现crud操作。由于玩不明白配置文件,所以俺就选择了使用@Select注解(菜)
1 | import com.example.mybatis1008.pojo.User; |
- service层:是业务逻辑层,完成功能的设计。也是先设计接口,再创建要实现的类。在service层中,我们可以调用mapper层中的接口来进行业务逻辑应用的处理。service的impl是对service接口进行实现,把mapper和service进行整合的文件。封装Service层的业务逻辑有利于业务逻辑的独立性和重复利用性。

1 | //UserService |
- controller层:是控制层,调用service层中实现的功能来实现业务,控制请求和响应,进行前后端交互
1 | import com.example.mybatis1008.service.UserServiceImpl; |
借用一张网图来清晰明了的总结一下结构~

mybatis
mybatis使用之前需要对项目进行一些配置,首先就是在maven中引入mybatis(具体maven文件在最后给出~),然后还需要在resources文件夹下新建一个mybatis-config.xml文件,其中的具体内容在mybatis的官网上可以找到,这里也给大家列出
1 |
|
这样我的mybatis就可以使用了(希望你滴也可以,这东西挺玄学的,第一次配的时候搞了半天),我采用的是直接在持久层使用@Select注解来写sql语句(见mapper层),自我感觉也挺方便清晰的,不过主流方案好像是在对应的配置文件中写,可能维护的时候更方便吧。
在使用时,直接创建mapper对象进行方法调用,即可实现其所对应的sql语句。
ajax
我更习惯用jQuery封装好的ajax,写法更简洁一点,原生的ajax区别也不算大。详见jQuery的ajax的简单应用
简单展示
- 初始状态

- 点击获取,获取现有的用户信息

- 填写用户名和密码,点击修改,修改信息
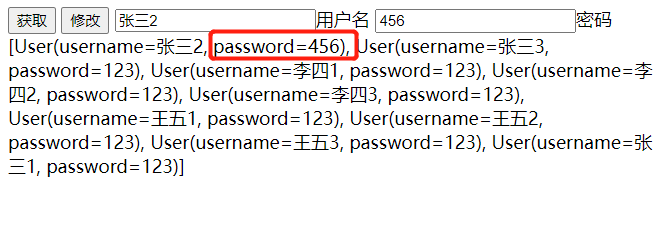
界面没有做什么美化,项目结构也很简单,但麻雀虽小五脏俱全,使用这些技术就可以实现一个小小的web项目了。(本文源码下载)
由于缺少研究,作者目前只是简单知道一些注解的作用,对于xml文件的编写并不是很熟悉,很多地方暂时也不是很清楚。但是作者认为,不理解的时候也不需深究,熟练的使用对理解原理有着重要作用。当能做到熟练使用时,也许我们对自己未知的知识会产生一些新的理解。
希望本文能帮助大家对web项目的开发有一些新的认识!
最后附上maven配置
1 |
|