Flink引擎
Flink引擎
Flink概述
- 什么是大数据
指无法在一定时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合。
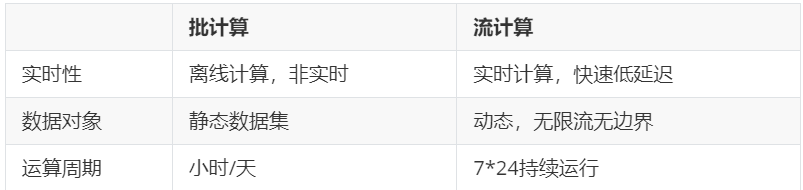
批计算和流计算的区别
- 为什么需要流计算
大数据的实时性带来价值更大,eg:实时推荐、数据监控
-
Flink的特点
-
- Exactly-Once
- 高吞吐低延迟,实时快速
- 高容错
- 流批一体
- Streaming/Batch SQL
Flink整体框架

-
Flink 分层框架
-
- SDK层:支持SQL/Table、DataStream(java)、Python

-
- 执行引擎层:提供统一DAG(有向无环图)来描述数据处理的Pipeline;调度层再把DAG转化成分布式环境下的Task;Task之间通过Shuffle传输数据

-
- 状态存储层:存储算子状态信息

-
- 资源调度层:Flink可以支持部署在多种环境

- Flink 整体框架
一个Flink集群主要包含两个核心组件:JM(JobManager)、TM(TaskManager)
-
JM 负责整个任务的协调工作,包括:调度 task、触发协调 Task 做 Checkpoint、协调容错恢复等,核心有下面三个组件:
-
- Dispatcher: 接收作业,拉起 JobManager 来执行作业,并在 Job Master 挂掉之后恢复作业;
- Job Master: 管理一个 job 的整个生命周期,会向 Resource Manager 申请 slot,并将 task 调度到对应 TM 上;
- Resource Manager:负责 slot 资源的管理和调度,Task manager 拉起之后会向 RM 注册;
-
TM 负责执行一个 DataFlow Graph 的各个 task 以及 data streams 的 buffer 和数据交换。

Flink 如何做到流批一体
-
流计算和批计算独立情况下:
-
- 人力成本高:批、流两套系统的逻辑相似,但是需要开发两遍;
- 数据链路冗余:本身计算内容是一致的,用两套逻辑相似的链路来处理,产生一定的资源浪费;
- 数据口径不一致:两套链路或多或少会产生误差,会给业务方带来困扰。
-
为什么可以实现流批一体:
-
- 站在 Flink 的角度,Everything is Streams,无边界数据集是一种数据流,可以按照时间分成一个个有界数据集;
- 而批计算可以看作是流计算的特例,其有界数据集也是一种特殊数据流。
- 因此,无论是无边界数据集还是有界数据集,Flink都可以支持,并且从API到底层处理都是统一的,实现了流批一体。
-
流批一体的 Scheduler 层
-
- Scheduler 主要负责将作业的 DAG 转化为在分布式环境中可以执行的 Task;
- EAGER模式(Streaming 场景):申请一个作业所需要的全部资源,然后同时调度这个作业的全部 Task,所有的 Task 之间采取 Pipeline 的方式进行通信;
- LAZY模式(Batch 场景):先调度上游,等待上游产生数据或结束后再调度下游,类似 Spark 的 Stage 执行模式。
-
流批一体的 Shuffle Service 层
-
- Shuffle:在分布式计算中,用来连接上下游数据交互的过程叫做 Shuffle。
- 为了统一在Streaming和Batch模式下的Shuffle架构,Flink实现了一个Pluggable的Shuffle Service框架,抽象出一些公共模块,详情如下

经过在 DataStream 层、Scheduler层、Shuffle Service 层进行改造和优化,Flink已经可以方便地解决流和批场景的问题。