常见的查询优化器
常见的查询优化器
什么是查询优化器
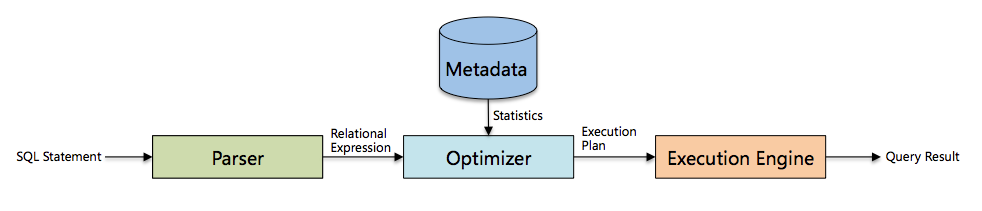
数据库主要由三部分组成,分别是解析器、优化器和执行引擎,其中优化器是把关系表达式转换成执行计划的核心组件,很大程度上决定了一个系统的性能。
查询优化器的分类
查询优化器主要分为两类,分别是:
RBO(基于规则的优化器,Rule-Based Optimizer)
CBO(基于规则的优化器,Cost-Based Optimizer)
RBO
- 根据关系代数等价语义,重写查询
- 基于启发式规则:主流RBO实现一般都有几百条基于经验归纳得到的优化规则
- 会访问表的元信息,不会涉及具体的表的数据
- 实现简单,优化速度快,但不保证得到最优的执行计划
列裁剪
列裁剪的基本思想在于:对于算子中实际用不上的列,优化器在优化的过程中没有必要保留它们。对这些列的删除会减少 I/O 资源占用,并为后续的优化带来便利。例如:
假设表 t 里面有 a b c 三列,执行语句:
1 | select a from t where b >5 |
在查询过程中,只用到了表 t 中 a b 两列的数据,而 c 列的数据未被用到。因此对于 c 列,我们可以将它裁剪掉,读取数据的时候不需要将它读进来。
谓词下推
谓词下推将查询语句中的过滤表达式计算尽可能下推到距离数据源最近的地方,以尽早完成数据的过滤,进而显著地减少数据传输或计算的开销。例如:
1 | select count(1) from A Join B on A.id = B.id where A.a >10 and B.b <100; |
在处理Join操作之前需要首先对A和B执行Scan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的Scan和B表的Scan的时候执行,则可以大大减少Join操作的输入数据。优化后的语句如下:
1 | select count(1) from (select * from A where a>10) as A1 Join(select * from B where b<100) as B1 on A1.id = B1.id; |
传递闭包
将表的过滤条件传递,在表连接前对两个表的数据都完成筛选,从而减少Join操作的输入数据。
Runtime Filter
Runtime Filter是通过在join前过滤掉那些不会命中join的输入数据来大幅减少join中的数据传输和计算,从而减少整体的执行时间。例如:
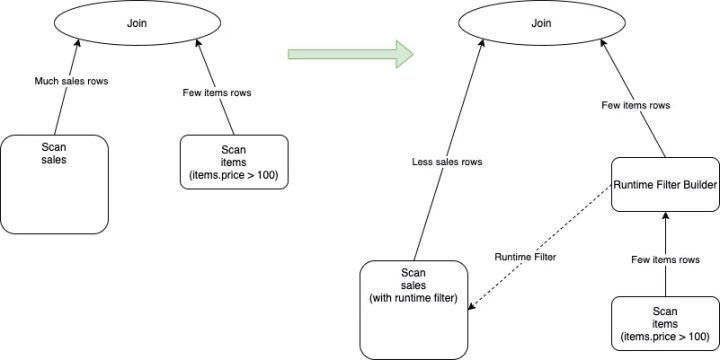
如上图左半部分所示,在进行join运算的时候不仅需要把全量的sales数据传输到join算子里去,而且每一行sales数据都需要进行join运算(包括算哈希值、比较运算等)。这里如果items.price > 100的选择率比较高,比如达到50%,那么sales表中的大部分数据是肯定不会被join上,如果提前进行过滤掉,可以减少数据的传输和计算的开销。
上图的右半部分则是加入了runtime filter之后的执行计划,从图中可以看到在进行join的build端拉取数据的过程中新增了一个RuntimeFilterBuilder的一个算子,这个算子的作用就是在运行的过程中收集build端的信息形成runtime filter,并且发送到probe端的scan节点中去,让probe端的节点可以在scan就减少输入的数据,从而实现性能的提升。
除此之外,还有Join消除、谓词合并等优化方式…
CBO
-
使用一个模型估算执行计划的代价,选择代价最小的执行计划
-
- 执行计划的代价等于所有算子的执行代价之和
- 通过RBO得到(所有)可能的等价执行计划
统计信息
原始表统计信息:
表或分区级别:行数、行平均大小、表在磁盘中占用字节大小
列级别:min、max、num nulls、num not nulls、num distinct value(NDV)等
推导统计信息:
选择率(selectivity):对于某一过滤条件,查询会从表中返回多大比例的数据
基数(cardinality):在查询计划中指算子需要处理的行数
执行计划枚举
考虑事项:
单表扫描:索引扫描 or 全表扫描
Join的实现:Hash Join or Sort Merge Join
多表Join:哪种连接顺序最优
通常使用贪心算法或者动态规划选出最优的执行计划。
大数据场景下使用CBO对查询性能非常重要
刚开始学数据库时还觉得关系代数没什么用,这下终于知道关系代数在SQL优化中的重要作用了